베이즈 정리를 사용한 확률 기반 분류기
목적
- 문장 X가 들어왔을 때
- 이 문장이 긍정(1) 일 확률 vs 부정(0) 일 확률을 비교하는 것
수식
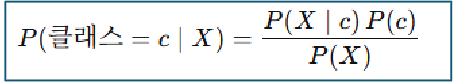
P(c) = 사전확률(prior)
→ 데이터 전체에서 긍정 리뷰가 얼마나 되는가?
예)
전체 리뷰 10만개 중
긍정 7만 → P(긍정) = 0.7
부정 3만 → P(부정) = 0.3
즉, 원래부터 긍정이 많았는지, 부정이 많았는지 반영하는 값.
P(X|c) = 우도(likelihood)
→ 문장 X 안의 단어들이 클래스 c에서 등장할 확률
예를 들어,
긍정 리뷰에서는 “재밌다”가 자주 나오고
부정 리뷰에서는 “지루하다”가 자주 나온다는 것.
즉,
해당 단어(들)가 그 클래스에서 얼마나 잘 나타나는지를 의미.
이게 사실상 분류의 핵심.
P(X) = 증거(evidence)
→ 모든 클래스(긍/부정)에서 X가 나올 확률
하지만 분류할 때는
긍정 vs 부정을 비교만 하면 되므로
P(X)는 두 클래스에 공통이라서 무시 가능.
즉,
P(X|긍정) * P(긍정)
vs
P(X|부정) * P(부정)
두 값만 비교하면 된다.
분류법
문장 X가 들어오면,
- P(X|긍정) * P(긍정) 계산
- P(X|부정) * P(부정) 계산
- 둘 중 더 큰 확률을 가진 클래스로 분류
예)
“너무 재밌어서 감동적이다” 문장이라면
- 긍정 클래스에서 “재밌다·감동적이다·너무” 같은 단어가 많이 등장
- 부정 클래스에서는 거의 안 쓰임
따라서:
P(X|긍정) * P(긍정)
≫ P(X|부정) * P(부정)
→ 그래서 “긍정”으로 분류됨.

나이브(naive) 가정
클래스가 주어졌을 때 문장 속 단어들은 서로 독립이라고 가정
- 즉, 단어들이 서로에게 영향을 주지 않는다고 보는 단순화된 모델
Multinomial Naive Bayes란?
──────────────────────────
문서를 숫자로 표현할 때
“단어가 몇 번 나왔는지(count)”로 표현하는 경우가 많지?
예: Bag-of-Words, CountVectorizer
- 영화, 영화, 재밌다, 최고
→ 영화(2회), 재밌다(1회), 최고(1회)
이처럼 단어 등장 횟수 기반 확률 모델이 바로
Multinomial Naive Bayes (다항 나이브 베이즈).
✔ 텍스트에서 가장 많이 쓰는 NB 모델
✔ 단어의 “빈도(count)”를 기반으로 분류함
✔ 형태: “단어가 많이 나왔으면 그 단어 빈도에 비례해 확률이 커짐”
──────────────────────────
■ 2) 클래스 c에 대해 확률을 계산하는 법
──────────────────────────
문장을 보고 긍정/부정을 분류할 때
각 단어 w가 긍정에서 얼마나 자주 등장했는지 계산해야 해.
이를 위해 필요한 값들이 아래처럼 정의돼.
● Nc : 클래스 c 안에서 등장한 전체 단어 수
예를 들어 “긍정 리뷰 전체” 안에 있는 단어 개수가
총 1,000,000개라면 → Nc = 1,000,000
여기서 “단어 개수”는
- 문서 개수 × 문서 길이
가 아니라 - 리뷰 전체에서 출현한 단어의 총합
즉 “긍정 리뷰 전체에서 단어가 몇 번 나왔는가” 만큼 더해진 값.
● Nc,w : 클래스 c 안에서 단어 w가 등장한 횟수
예)
- 긍정 리뷰에서 “재밌다”가 5000번 등장
→ Nc,“재밌다” = 5000 - 부정 리뷰에서 “재밌다”가 300번 등장
→ Nc,“재밌다” = 300
이 값들을 기반으로 단어의 감성 경향이 드러남.
● V : 전체 단어 사전 크기(Unique 단어 수)
데이터 전체에서
서로 다른 모든 단어가 몇 개인지.
예)
전체 리뷰에서 단어 종류가 80,000개면
→ V = 80,000
──────────────────────────
■ 3) 단어 w가 클래스 c에서 나올 확률 공식
──────────────────────────
공식:
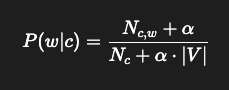
뜻을 풀어보면:
- 분자:
→ 해당 단어가 그 클래스에서 얼마나 많이 등장했는가
(+ α 만큼 최소 보정) - 분모:
→ 그 클래스에서 등장한 전체 단어 수
(+ α × 전체 단어 종류 수)
즉,
**클래스 c에서 단어 w의 “등장률”**을 계산하는 공식.
──────────────────────────
■ 4) 스무딩(smoothing) 파라미터 α의 의미
──────────────────────────
여기서 α는 중요한 하이퍼파라미터야.
왜 필요한가?
● 문제: 한 번도 안 나온 단어의 확률이 0이 되어버림
예)
부정 리뷰에서 “최고다”가 한 번도 안 나왔다면:
Nc,“최고다” = 0
그러면
P(“최고다” | 부정) = 0
→ 이 단어가 들어간 문장은 무조건 부정 확률 0이 되어버림
이러면 모델이 망함.
● 해결: α 추가해 “0”이 되지 않게 보정
- α=1 (라플라스 스무딩) → 단어 등장 횟수에 모두 +1
- α=0.1 → 미세한 보정
- α=0 → 스무딩 없음 (문제 생김)
즉, α는 단어가 한 번도 나오지 않았을 때도 확률을 부드럽게 만들어주는 역할.

MultinomialNB()의 하이퍼 파라미터
■ 1) alpha (스무딩 강도)
───────────────────────────────
● alpha란?
- 라플라스(Laplace) 또는 리드스톤(Lidstone) 스무딩 강도 조절 파라미터
- 단어가 한 번도 등장하지 않았을 때 확률이 0이 되어버리는 문제를 막아주는 역할
공식에서:
P(w∣c)=Nc,w+αNc+α⋅∣V∣P(w|c) = \frac{N_{c,w} + \alpha}{N_c + \alpha \cdot |V|}
여기에서 α가 바로 이 값.
● alpha가 큰 경우 (예: α = 1, 2)
- 분모, 분자에 추가되는 값이 커짐 → 확률이 더 평평해짐
- 희귀 단어의 영향이 약해짐
- 특이한 단어가 이리저리 튀는 것을 막고, 전체적으로 안정적
- 저빈도 단어가 너무 강하게 작용할 때 해결책
→ “아주 드문 단어”가 모델을 망치는 것을 막는 효과
● alpha가 작은 경우 (예: α = 0.1, 0.01)
- smoothing이 약해짐
- 실제 count 값에 더 민감
- 데이터에 있는 단어 분포가 강하게 반영됨
- 대신 노이즈에도 더 민감해서 성능이 불안정할 수 있음
→ 데이터가 아주 깨끗하고 단어가 충분히 많을 때 유리
예시
param_grid = {
"vect__ngram_range": [(1, 1), (1, 2)],
"nb__alpha": [0.1, 0.5, 1.0, 2.0]
}
■ 2) fit_prior (True / False)
● fit_prior = True (기본값)
- 각 클래스의 사전확률 P(c)를 데이터에서 자동으로 계산해서 사용
- 즉, 긍정 리뷰가 70%, 부정 리뷰가 30%라면 이 비율을 그대로 반영함
→ 레이블 불균형이 있을 때 정상적으로 쓰는 방식
예) 긍정 90%, 부정 10% 데이터라면
P(긍정)=0.9, P(부정)=0.1 로 자동 설정
● fit_prior = False
- 모든 클래스의 사전확률을 동일하게 50:50으로 가정
- 즉, P(긍정)=P(부정)=0.5 로 고정
- 데이터 비율을 무시하고 균등한 확률 기반으로만 분류
→ 데이터 비율의 영향력을 없애고 싶을 때 사용
→ “클래스가 매우 불균형한 데이터”에서 sometimes 도움이 됨
실습
import numpy as np # 숫자 연산용 라이브러리
from sklearn.feature_extraction.text import CountVectorizer # 단어 개수 벡터화
from sklearn.naive_bayes import MultinomialNB # 다항 나이브베이즈
from sklearn.pipeline import Pipeline # 벡터화 + 모델 묶기
from sklearn.model_selection import train_test_split # 데이터 분할
from sklearn.metrics import classification_report # 평가 지표 출력
texts = [ # 리뷰 문장들
"서비스가 너무 느리고 불친절했어요", # 부정 0
"맛이 없고 양도 너무 적어요", # 부정 0
"직원들이 정말 친절하고 음식도 맛있어요", # 긍정 1
"가격도 적당하고 분위기가 좋아요", # 긍정 1
"다시는 오고 싶지 않아요", # 부정 0
"완전 만족스러운 식사였습니다", # 긍정 1
]
labels = [0, 0, 1, 1, 0, 1] # 각 문장의 레이블(0=부정, 1=긍정)
x_train, x_test, y_train, y_test = train_test_split(
texts,
labels,
test_size=0.2, # 테스트 20%
stratify=labels, # 클래스 비율 유지
random_state=42, # 재현성
)
nb_clf = Pipeline(
[
("vect", CountVectorizer()), # 문장을 단어 count 벡터로 변환
("nb", MultinomialNB(alpha=1.0)), # 다항 나이브베이즈 모델 + 스무딩(alpha)
]
)
nb_clf.fit(x_train, y_train) # 벡터화 + 모델 학습
y_pred = nb_clf.predict(x_test) # 테스트 데이터 예측
print(classification_report(y_test, y_pred, digits=3)) # 정밀도/재현율/F1 출력
probs = nb_clf.predict_proba(
[
"배송이 빠르고 친절해서 만족스럽다", # 새 문장 1
"제품이 고장나서 너무 화가 난다.", # 새 문장 2
]
)
print(probs) # 각 문장의 [P(0), P(1)] 확률 출력
vect = nb_clf.named_steps["vect"] # Pipeline에서 CountVectorizer 꺼내기
nb = nb_clf.named_steps["nb"] # Pipeline에서 MultinomialNB 꺼내기
feature_names = np.array(vect.get_feature_names_out()) # vectorizer가 만든 단어 사전
print("feature_names", feature_names) # 단어 목록 출력
print("nb.classes_", nb.classes_) # 모델이 가진 클래스 정보 [0,1]
print("nb.class_log_prior_", nb.class_log_prior_) # 클래스별 log P(c)
print("np.exp(nb.class_log_prior_", np.exp(nb.class_log_prior_)) # 실제 P(c)로 복원
print(
"np.exp(nb.feature_log_prob_)", np.exp(nb.feature_log_prob_)
) # 각 단어의 P(w|c) (클래스별 단어 확률)
for i, class_label in enumerate(nb.classes_): # 클래스 0/1 반복
log_prob = nb.feature_log_prob_[i] # 해당 클래스의 단어별 log P(w|c)
top10_idx = log_prob.argsort()[-10:] # 가장 확률 높은 단어 상위 10개
print(f"=== 클래스 {class_label} 대표 단어 ===")
print(feature_names[top10_idx]) # top 10 단어 출력'데이터 분석 > 머신러닝, 딥러닝' 카테고리의 다른 글
| LDA (Latent Dirichlet Allocation) (0) | 2025.11.26 |
|---|---|
| LSA (Latent Semantic Analysis) (0) | 2025.11.26 |
| TF-IDF (0) | 2025.11.20 |
| Bag-of-Word(BOW) (0) | 2025.11.19 |
| 텍스트 전처리 (0) | 2025.11.18 |